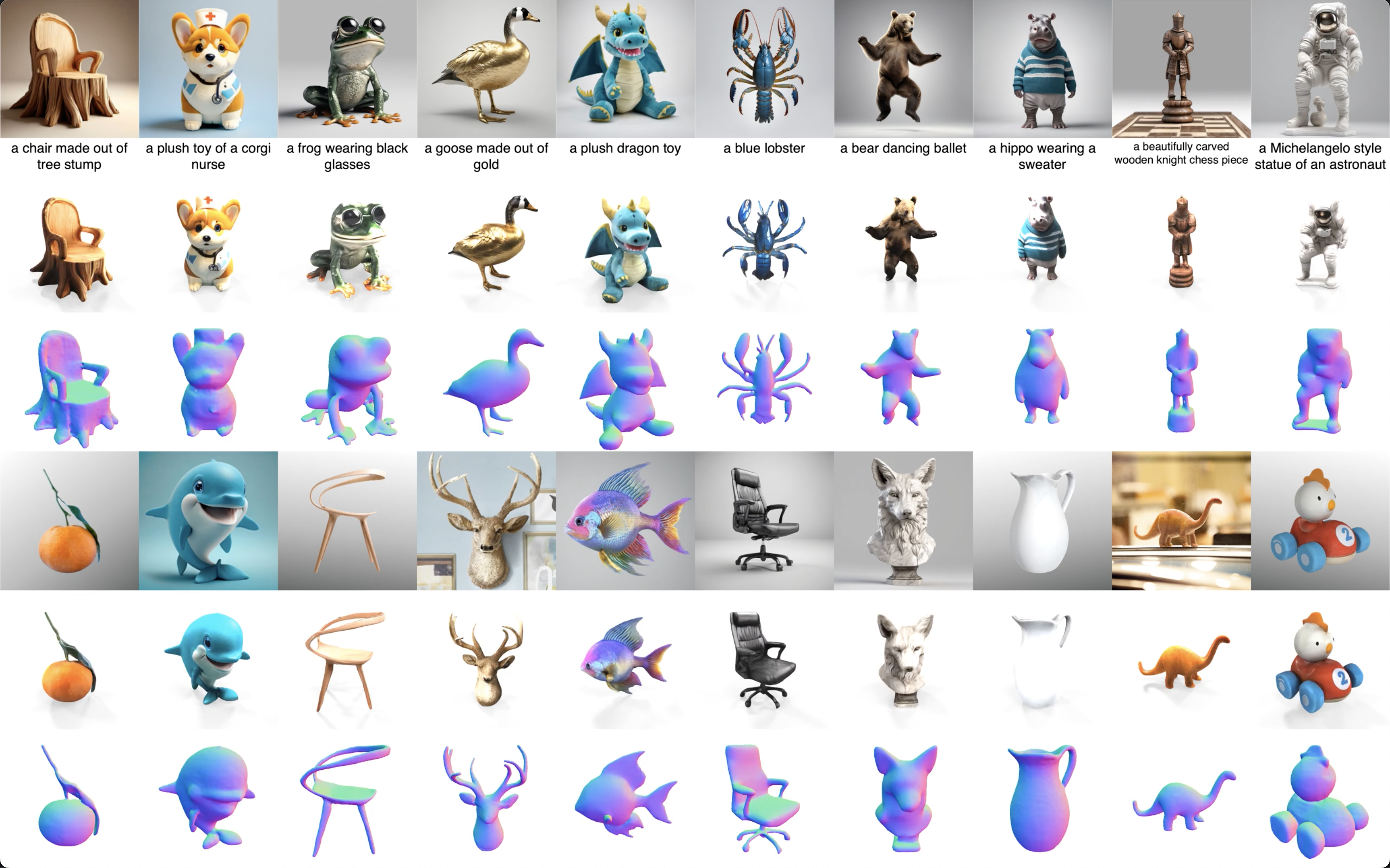
MeshFormer: High-Quality Mesh Generation with 3D-Guided Reconstruction Model
NeurIPS 2024 Oral
A sparse-view reconstruction model that explicitly leverages 3D native structure, input guidance, and training supervision.