|
I earned my Ph.D. degree in Statistics at UCLA in 2025. Previously, I received dual bachelor degrees in Computer Engineering from University of Illinois at Urbana-Champaign and Zhejiang University. My research interests are focused on the fields of computer vision, robotics, and cognition. I actively engaged in pushing the boundaries of generalizable 3D vision: 1) object understanding, 2) 3D reconstruction and generation, etc. Email / CV / GitHub / Google Scholar / / / |

|
|
|

|
Minghua Liu*, Chong Zeng*, Xinyue Wei, Ruoxi Shi, Linghao Chen, Chao Xu, Mengqi Zhang, Zhaoning Wang, Xiaoshuai Zhang, Isabella Liu, Hongzhi Wu, Hao Su NeurIPS 2024 Oral Paper / Project / Demo A sparse-view reconstruction model that explicitly leverages 3D native structure, input guidance, and training supervision. |

|
Chao Xu, Ang Li, Linghao Chen, Yulin Liu, Ruoxi Shi, Hao Su†, Minghua Liu† ECCV 2024 [also featured in CV4Metaverse (Oral) and Wild3D] Paper / Project / Demo Given sparse unposed views, we leverage rich priors embedded in multiview diffusion models to predict their poses and reconstruct the 3D shape. |
|
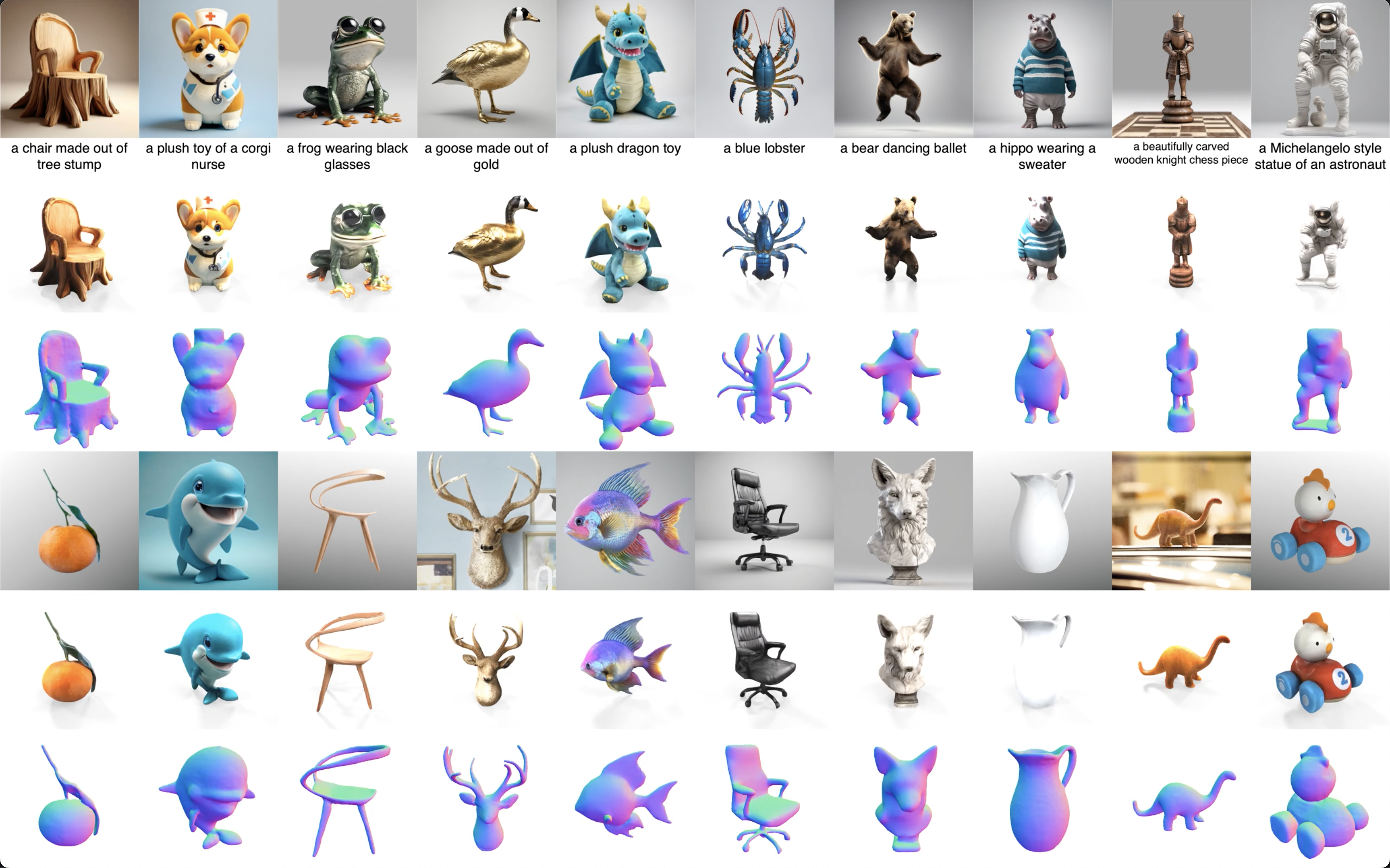
Minghua Liu*, Ruoxi Shi*, Linghao Chen*, Zhuoyang Zhang*, Chao Xu*, Xinyue Wei, Hansheng Chen, Chong Zeng, Jiayuan Gu, Hao Su CVPR 2024 Paper / Project / Code Star / Demo We propose a new pipeline in the One-2-3-45's paradigm: More consistent multi-view generation (Zero123++) and better reconstruction (multi-view conditioned 3D native diffusion models). |

|
Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xinyue Wei, Linghao Chen, Chong Zeng, Hao Su Technical Report Paper / Code Star We improve consistency and image conditioning in single-image multi-view generation. |

|
Minghua Liu*, Chao Xu*, Haian Jin*, Linghao Chen*, Mukund V. T, Zexiang Xu, Hao Su NeurIPS 2023 Paper / Project / Code Star We rethink how to leverage 2D diffusion models for 3D AIGC and introduce a novel forward-only paradigm that avoids the time-consuming optimization. |

|
Haoran Geng*, Helin Xu*, Chengyang Zhao*, Chao Xu, Li Yi, Siyuan Huang, He Wang CVPR 2023 Highlight (10% of accepted, scores: 5, 5, 5) Paper / Project / Code We learn parts on articulated objects across categories. |
|
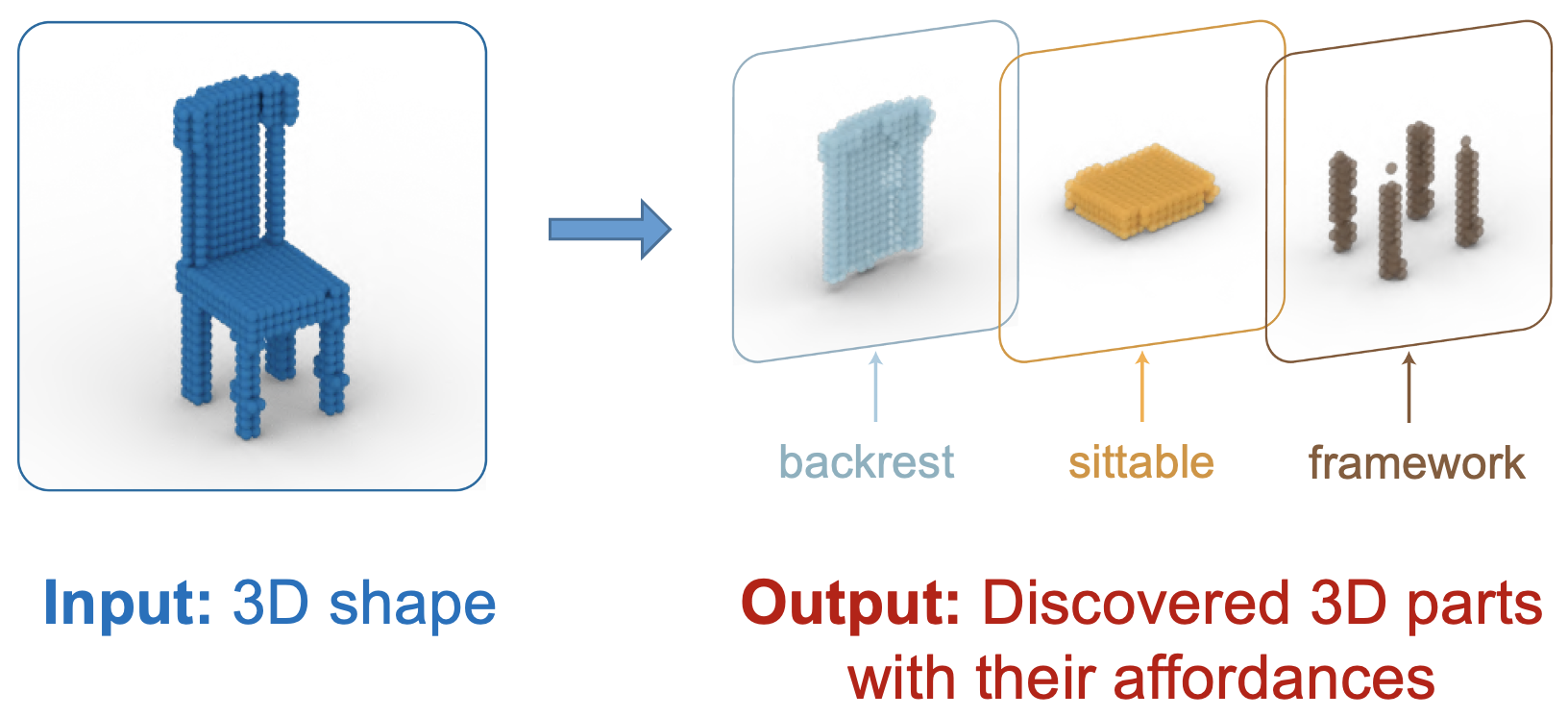
Chao Xu, Yixin Chen, He Wang, Song-Chun Zhu, Yixin Zhu, Siyuan Huang ECCV 2022 Visual Object-oriented Learning meets Interaction Workshop Paper / Video We discover part affordances on 3D objects across categories under weak supervision. |